Posts tagged community
Quick takes
Popular comments
Recent discussion
Written by Claude, and very lightly edited.
In a recent episode of The Diary of a CEO podcast, guest Bryan Johnson, founder of Kernel and the Blueprint project, laid out a thought-provoking perspective on what he sees as the most important challenge and opportunity of our...
I can't find a better place to ask this, but I was wondering whether/where there is a good explanation of the scepticism of leading rationalists about animal consciousness/moral patienthood. I am thinking in particular of Zvi and Yudkowsky. In the recent podcast with Zvi...
This is the latest of a theoretically-three-monthly series of posts advertising EA infrastructure projects that struggle to get and maintain awareness (see original advertising post for more on the rationale).
I italicise organisations added since the previous post was originally...
Do you know what kind of management she does of it? Can anyone add themselves, or does she curate it in some way?
Summary of the summary
- This post is a summary of the most important results from my undergraduate thesis on AI-NC3 (nuclear command, control, and communications) integration. Specifically, I studied the risk of automation bias (an over-reliance on AI decision support) experimentally
Please feel free to add comments or ask questions, even if you think your question is probably already answered in the full manuscript. I have no problem answering or pointing you to the answer.
Crosspost of my blog.
You shouldn’t eat animals in normal circumstances. That much is, in my view, quite thoroughly obvious. Animals undergo cruel, hellish conditions that we’d confidently describe as torture if they were inflicted on a human (or even a dog). No hamburger...
I found going vegan very difficult so I relate to your experience but I think your argument for it not actually being the right thing for you to do on altruistic grounds is weak. It’s worth introspecting on the extent to which “focusing” on getting used to veganism entails a meaningful trade off with doing good. I think people’s lives and schedules have a lot more slack in them than we like to admit, and I think far from all of the time/energy put into being vegan would have otherwise been spent on altruism. Meanwhile, once you’re used to being vegan, you’...
First in-ovo sexing in the US
Egg Innovations announced that they are "on track to adopt the technology in early 2025." Approximately 300 million male chicks are ground up alive in the US each year (since only female chicks are valuable) and in-ovo sexing would prevent this...
For others who were curious about what time difference this makes: looks like sex identification is possible at 9 days after the egg is laid, vs 21 days for the egg to hatch (plus an additional ~2 days between fertilization and the laying of the egg.) Chicken embryonic development is really fast, with some stages measured in hours rather than days.
I asked Google when chicken embryos start to feel pain and this was the first result (i.e. I didn't look hard and I didn't anchor on a figure):
A recent study by the Technical University of Munich in Germany measured chicken embryos' heart rate, brain activity, blood pressure and movements in response to potentially painful stimuli like heat and electricity and concluded that they didn't seem to feel them until at least day 13. (14 Oct 2023)
Egg Innovations, which sells 300 million free-range and pasture-raised eggs a year
This interview with the CEO suggests that Egg Innovations are just in the laying (not broiler) business and that each hen produces ~400 eggs over her lifetime. So this will save ~750,000 chicks a year?
I just spent a couple of hours trying to understand the UN’s role in the governance of AI. The most important effort seems to be the Global Digital Compact (GDC). An initiative for member states to “outline shared principles for an open, free and secure digital future for all". The GDC has been developed by member states since at least 2021 and will be finalized at the upcoming Summit for the Future in September. Recently, the first draft (Zero Draft) was shared and will be discussed and iterated in the final months before the Summit. The Simon Institute wrote an excellent seven-page response to this. I warmly recommend reading their response but here’s my imperfect summary (the figures are copied from their response).
What does the draft propose?
Four new entities or mechanisms

Strengthening of existing entities or mechanisms
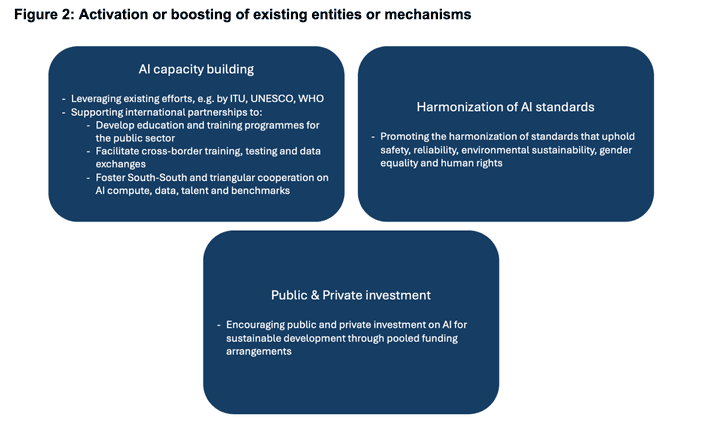
What are the strengths of the draft?
- It covers a
Originally posted on my blog
A very interesting discussion I came across online between Cosmicskeptic (Alex) and Earthlings Ed (Ed Winters) brought forth several points that I have wondered about in the past. In one segment, Alex poses the following question: ...
Is there any empirical evidence to back up the claim that following the conventional definition of veganism leads to greater overall harm reduction rather than thinking in more consequential terms ? Also, unless I am mistaken, the utilitarian argument for rule-of-thumb applies in a context where we are either faced with an inability to determine the right course of action (owing to uncertainties in estimates of potential outcomes, say) or when the decision that emerges from such a calculation runs strongly counter to common sense.
I don’t believe either is the case with the definition of veganism. It is not common-sensical to avoid products with trace elements of animal ingredients for example.
I take a very longtermist and technology-development focused view on things, so the GHD achievements weigh a lot less in my calculus.
The vast majority of world-changing technology was developed or distributed through for-profit companies. My sense is nonprofits are also more likely to cause harm than for-profits (for reasons that would require its own essay to go into, but are related to their lack of feedback loops).