Posts tagged community
Quick takes
Popular comments
Recent discussion
For others who were curious about what time difference this makes: looks like sex identification is possible at 9 days after the egg is laid, vs 21 days for the egg to hatch (plus an additional ~2 days between fertilization and the laying of the egg.) Chicken embryonic development is really fast, with some stages measured in hours rather than days.
Egg Innovations, which sells 300 million free-range and pasture-raised eggs a year
This interview with the CEO suggests that Egg Innovations are just in the laying (not broiler) business and that each hen produces ~400 eggs over her lifetime. So this will save ~750,000 chicks a year?
I can't find a better place to ask this, but I was wondering whether/where there is a good explanation of the scepticism of leading rationalists about animal consciousness/moral patienthood. I am thinking in particular of Zvi and Yudkowsky. In the recent podcast with Zvi Mowshowitz on 80K, the question came up a bit, and I know he is also very sceptical of interventions for non-human animals on his blog, but I had a hard time finding a clear explanation of where this belief comes from.
I really like Zvi's work, and he has been right about a lot of things I was initially on the other side of, so I would be curious to read more of his or similar people's thoughts on this.
Seems like potentially a place where there is a motivation gap: non-animal welfare people have little incentive to convince me that they think the things I work on are not that useful.
Written by Claude, and very lightly edited.
In a recent episode of The Diary of a CEO podcast, guest Bryan Johnson, founder of Kernel and the Blueprint project, laid out a thought-provoking perspective on what he sees as the most important challenge and opportunity of our...
FWIW I think this kind of post is extremely valuable. I may not see him as very EA-aligned but identifying very rich people who might be a bit EA-aligned is very good because the movement could seek to engage with them more and potentially get funding for some impactful stuff.
I just spent a couple of hours trying to understand the UN’s role in the governance of AI. The most important effort seems to be the Global Digital Compact (GDC). An initiative for member states to “outline shared principles for an open, free and secure digital future for all". The GDC has been developed by member states since at least 2021 and will be finalized at the upcoming Summit for the Future in September. Recently, the first draft (Zero Draft) was shared and will be discussed and iterated in the final months before the Summit. The Simon Institute wrote an excellent seven-page response to this. I warmly recommend reading their response but here’s my imperfect summary (the figures are copied from their response).
What does the draft propose?
Four new entities or mechanisms

Strengthening of existing entities or mechanisms
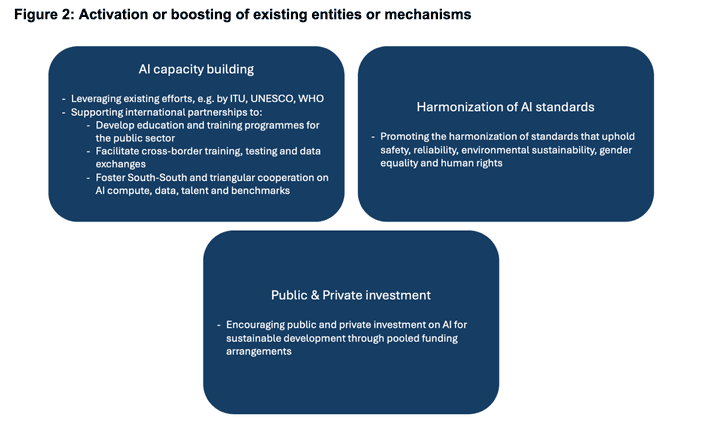
What are the strengths of the draft?
- It covers a
The Centre for Exploratory Altruism Research (CEARCH) is an EA organization working on cause prioritization research as well as grantmaking and donor advisory. This project was commissioned by the leadership of the Meta Charity Funders (MCF) – also known as the Meta Charity...
Just want to say here (since I work at 80k & commented abt our impact metrics & other concerns below) that I think it's totally reasonable to:
- Disagree with 80,000 Hours's views on AI safety being so high priority, in which case you'll disagree with a big chunk of the organisation's strategy.
- Disagree with 80k's views on working in AI companies (which, tl;dr, is that it's complicated and depends on the role and your own situation but is sometimes a good idea). I personally worry about this one a lot and think it really is possible we could be wrong h
Originally posted on my blog
A very interesting discussion I came across online between Cosmicskeptic (Alex) and Earthlings Ed (Ed Winters) brought forth several points that I have wondered about in the past. In one segment, Alex poses the following question: ...
Is there any empirical evidence to back up the claim that following the conventional definition of veganism leads to greater overall harm reduction rather than thinking in more consequential terms ? Also, unless I am mistaken, the utilitarian argument for rule-of-thumb applies in a context where we are either faced with an inability to determine the right course of action (owing to uncertainties in estimates of potential outcomes, say) or when the decision that emerges from such a calculation runs strongly counter to common sense.
I don’t believe either is the case with the definition of veganism. It is not common-sensical to avoid products with trace elements of animal ingredients for example.
The last ten years have witnessed rapid advances in the science of animal cognition and behavior. Striking results have hinted at surprisingly rich inner lives in a wide range of animals, driving renewed debate about animal consciousness.
To highlight these advances...
As an outsider to the field, here are some impressions I have:
- NY declaration is very short and uses simple language, which makes it a useful tool for communicating with the public. Compare to this sentence from the Cambridge declaration:
The neural substrates of emotions do not appear to be confined to cortical structures. In fact, subcortical neural networks aroused during affective states in humans are also critically important for generating emotional behaviors in animals.
- The Cambridge declaration is over a decade old. Releasing a similar statement is an
We've been told by VCs and founders in the AI space that Human-level Artificial Intelligence (formerly AGI), followed by Superintelligence, will bring about a techno-utopia, if it doesn't kill us all first.
In order to fulfill that dream, AI must be sentient, and that requires it have consciousness. Today, AI is neither of those things so how do we get there from here?
Questions about AI consciousness and sentience have been discussed and debated by serious researchers, philosophers, and scientists for years; going back as far as the early sixties at RAND Corporation when MIT Professor Hubert Dreyfus turned in his report on the work of AI pioneers Herbert Simon and Allan Newell entitled "Alchemy and Artificial Intelligence."
Dreyfus believed that they spent too much time pursuing AGI and not enough time pursuing what we would call "narrow AI". This quote comes from the conclusion of his paper...
First in-ovo sexing in the US
Egg Innovations announced that they are "on track to adopt the technology in early 2025." Approximately 300 million male chicks are ground up alive in the US each year (since only female chicks are valuable) and in-ovo sexing would prevent this...